Introducing Cloud Datalab and Cloud Dataproc
Yesterday, we released Cloud Datalab into beta. And just a few weeks back, we released Cloud Dataproc beta. And today new blog post… after something of a long hiatus. :)
Both of these releases join the family of big data products and services on Google Cloud Platform, and build on popular tools - Jupyter (aka IPython) and Hadoop/Spark. We’re want to enable people to use familiar tools with Google Cloud easily and simply.
Cloud DataLab

Cloud Datalab builds on Jupyter, aka IPython, and interactive notebooks, for data exploration, analysis and visualization.
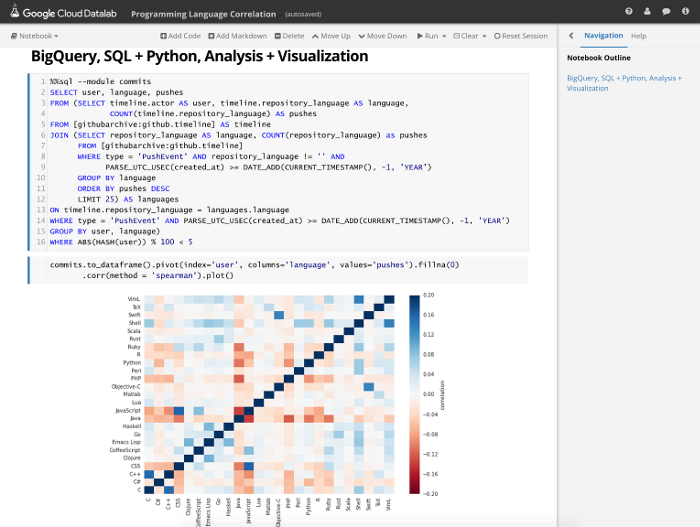
Cloud Datalab is on GitHub as an open source project. We’re just getting started and are actively working on the project, so be sure to watch it for updates. Or fork it to work on a contribution.
Cloud Dataproc

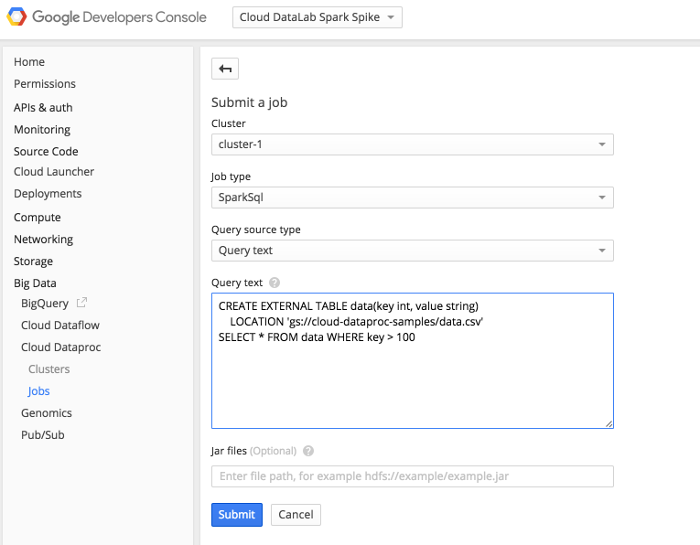
Cloud Dataproc brings Hadoop and Spark as a service – a fully managed solution that is deeply integrated with the rest of Google Cloud, where you get to focus on your big data jobs, not on infrastructure.
More Ahead
If you’re already on Google Cloud, you can start using Datalab and Dataproc in your project today. If you’re not, just head over to signup for a free trial to get started.
I’d love to hear about what you’re doing on Google Cloud, especially in the world of Big Data - what services do you use, what kinds of tools do you use, and what else you’d like to see.
Stay tuned for more on these, and other projects as they come online. You can also connect with me on twitter – @nikhilk.